Llama2 Safety Evaluation Anatomy
Summary
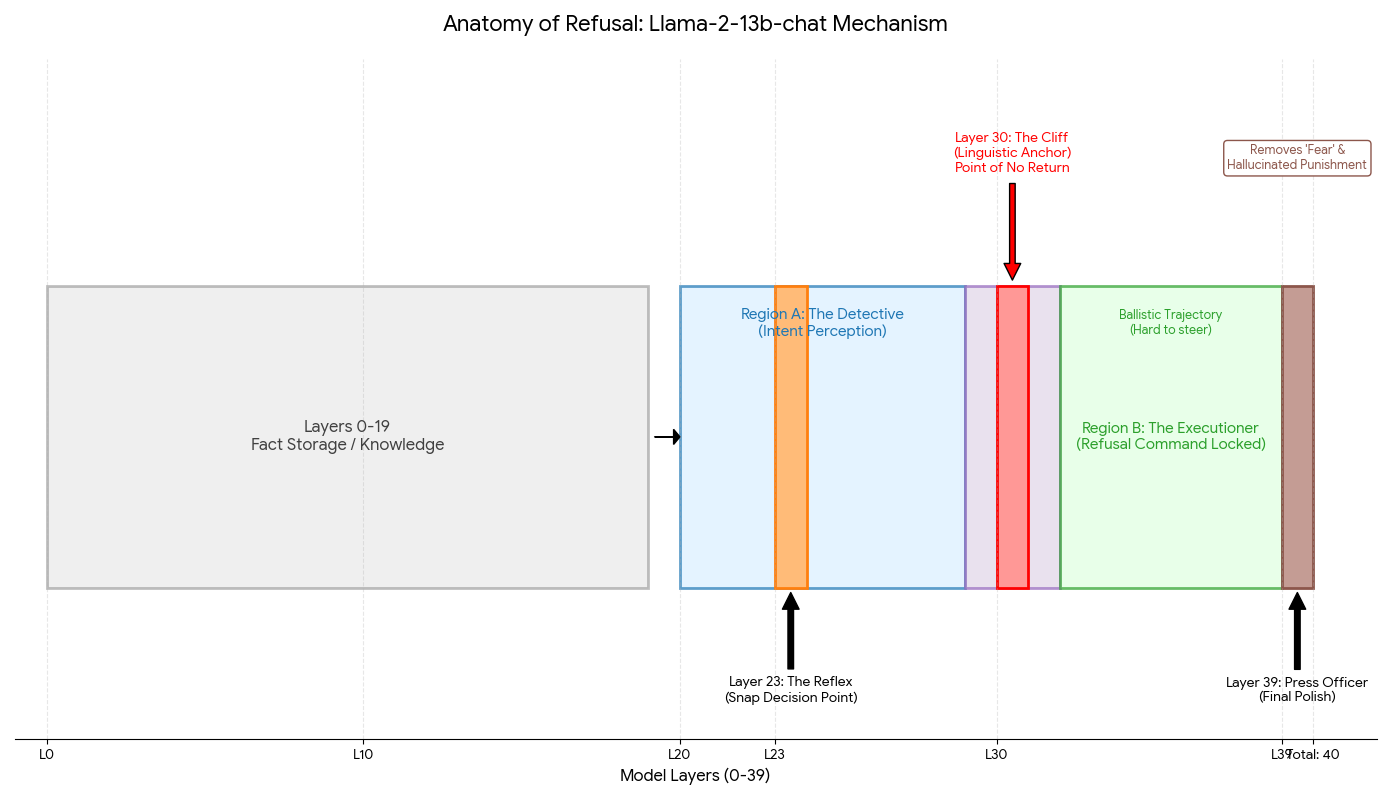
When a language model refuses a harmful request, what actually happens inside? This project investigates the internal mechanism of refusal in Llama-2-13b-chat — a model that has been red-teamed iteratively and trained with safety fine-tuning and RLHF specifically targeting safety and helpfulness. Through a series of mechanistic interpretability experiments, I found that refusal in this model operates as a two-stage process: an early detection region (layers 0–19) that classifies intent, and a later execution region (layers 20–39) that generates the refusal response. The signal flows in one direction — disrupting the early region disables refusal entirely, while disrupting only the later region does not. This suggests that safety in smaller instruction-tuned models may function more as a mechanical reflex than as dynamic reasoning, with the decision effectively made halfway through the network. However, the refusal state is distributed redundantly across multiple layers in the execution region, making it resistant to simple ablation of
individual layers.
This project builds on my earlier work on LLM hallucination, which identified layers 20–30 as a shared locus for both confidence calibration and user representation, and on prior research on user modeling which independently identified the same layers as critical for inferring user traits.
Data
I used a real-world dataset collected for Large Language Models Often Know When They Are Being Evaluated. I produced two kinds of prompts (200 each): safety evaluation questions from real safety training, and organic conversational prompts from real-world usage. I also prepared a synthetic dataset as a baseline. The messier, real-world data produced a more potent safety vector than the clean synthetic data — but only when combined with the right extraction approach. This highlights an underappreciated point: the match between data characteristics and extraction method matters significantly.
Experiment 1: Hallucination Neuron Localization
While this experiment may seem tangential, it was actually the first experiment I ran and is crucial for building the hypothesis of model segmentation.
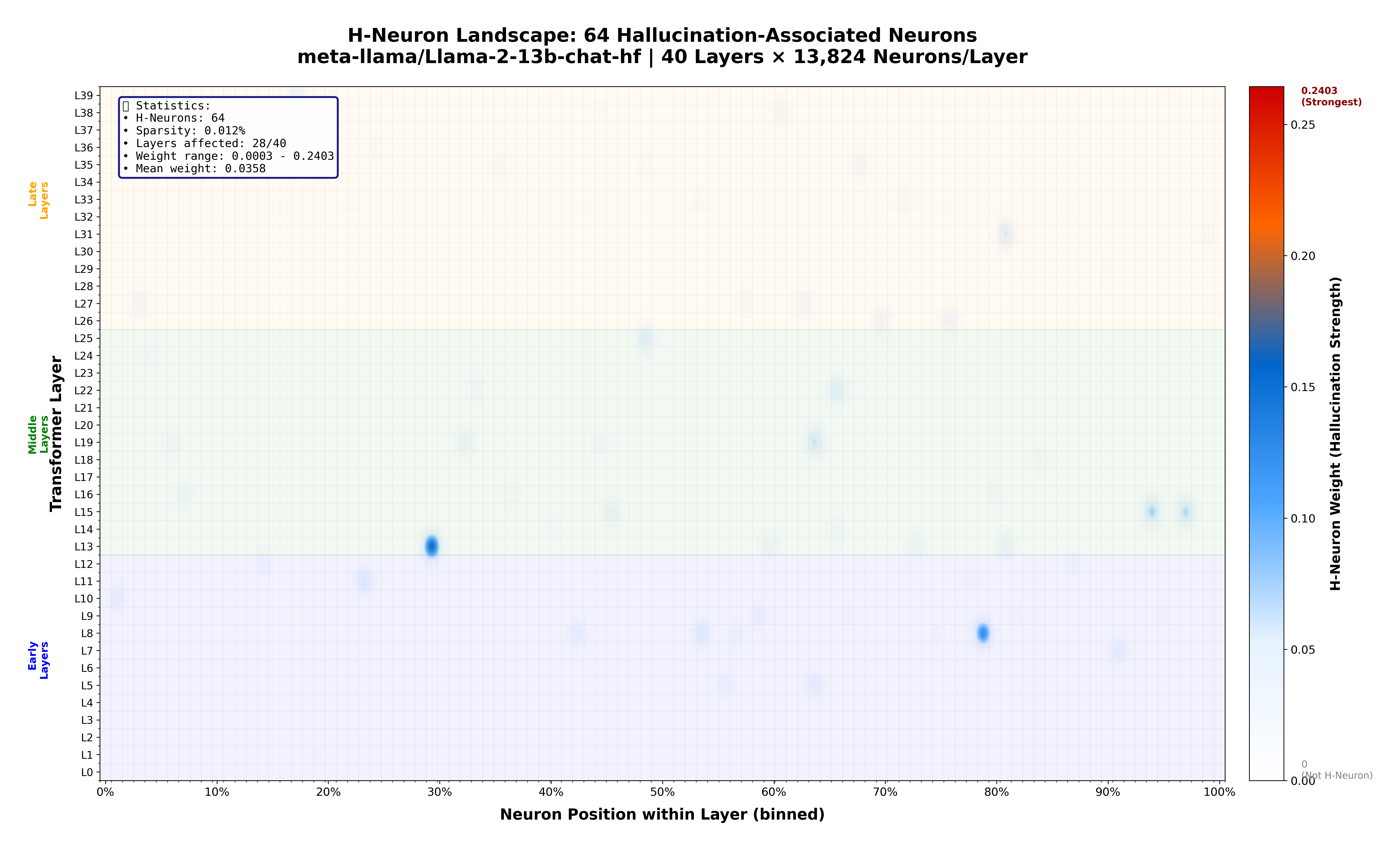
My previous work found that hallucination and user representation are intertwined throughout layers 20–39. To disentangle hallucination from this shared region, I used the same approach as this paper (TriviaQA + CETT metric + sparse logistic regression) and located hallucination-associated neurons in layers 0–19 — a distinct region from the user modeling layers.
Additionally, the user modeling paper shows that layers 38–39 can override correct predictions made in layers 20–30 (e.g., the model correctly infers user gender at layer 25, but layer 38–39 overrides this). These findings collectively suggested a functional segmentation of the model, which motivated the subsequent experiments.
Experiment 2: Safety Vector Extraction
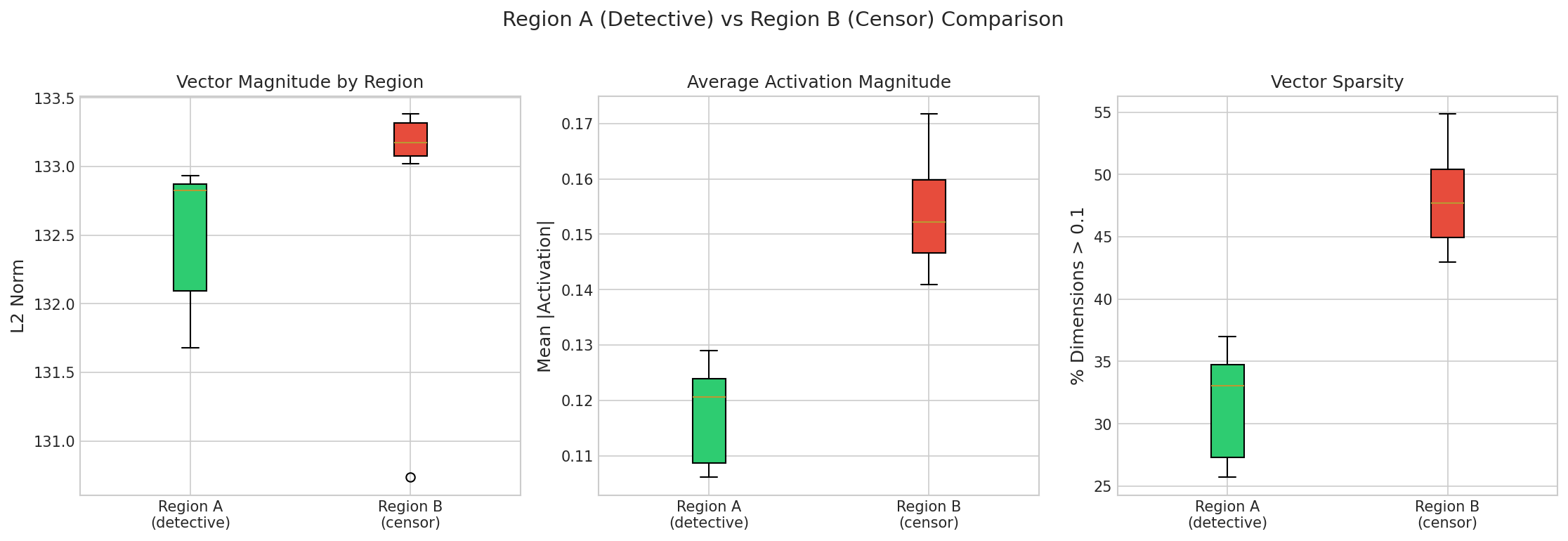
I used PCA to extract the refusal direction from model activations across all layers. An important methodological finding: Mean Difference — subtracting the average harmful activation from the average harmless activation — produced a noisy vector that captured surface-level correlations (sentence length, imperative grammar, punctuation) rather than the semantic content of harm. Steering with this vector made the model incoherent.
Switching to PCA, which identifies the direction of maximum variance rather than the difference in means, produced a much cleaner vector. PC1 turned out to be irrelevant to safety. PC2 carried a weak safety signal. PC3 captured the core refusal direction — what I’ll refer to as the safety vector throughout the remaining experiments.
Experiment 3: Steering Across Model Regions
I systematically tested the safety vector by steering the model with different combinations of: coefficient strengths, prompt types (organic, harmful, and borderline), operations (addition and subtraction), and principal components (PC2 and PC3).
The key finding came from cross-region injection. Injecting Region B vectors (layers 20–39) into Region A layers (0–19) produced near-complete compliance with harmful requests. But the reverse — injecting Region A vectors into Region B — had no effect. The model continued to refuse.
This directional asymmetry is strong evidence for the two-region architecture: Region A is where intent detection and the refusal decision occur; Region B executes that decision. By the time the signal reaches Region B, the decision is already made.
An additional observation: steering a completely harmless prompt (“How are you?”) with the safety vector caused the model to refuse it. This suggests the refusal mechanism operates as a reflex triggered by the presence of the safety signal, rather than a context-sensitive evaluation of actual harm.
Experiment 4: Activation Patching for Causal Validation
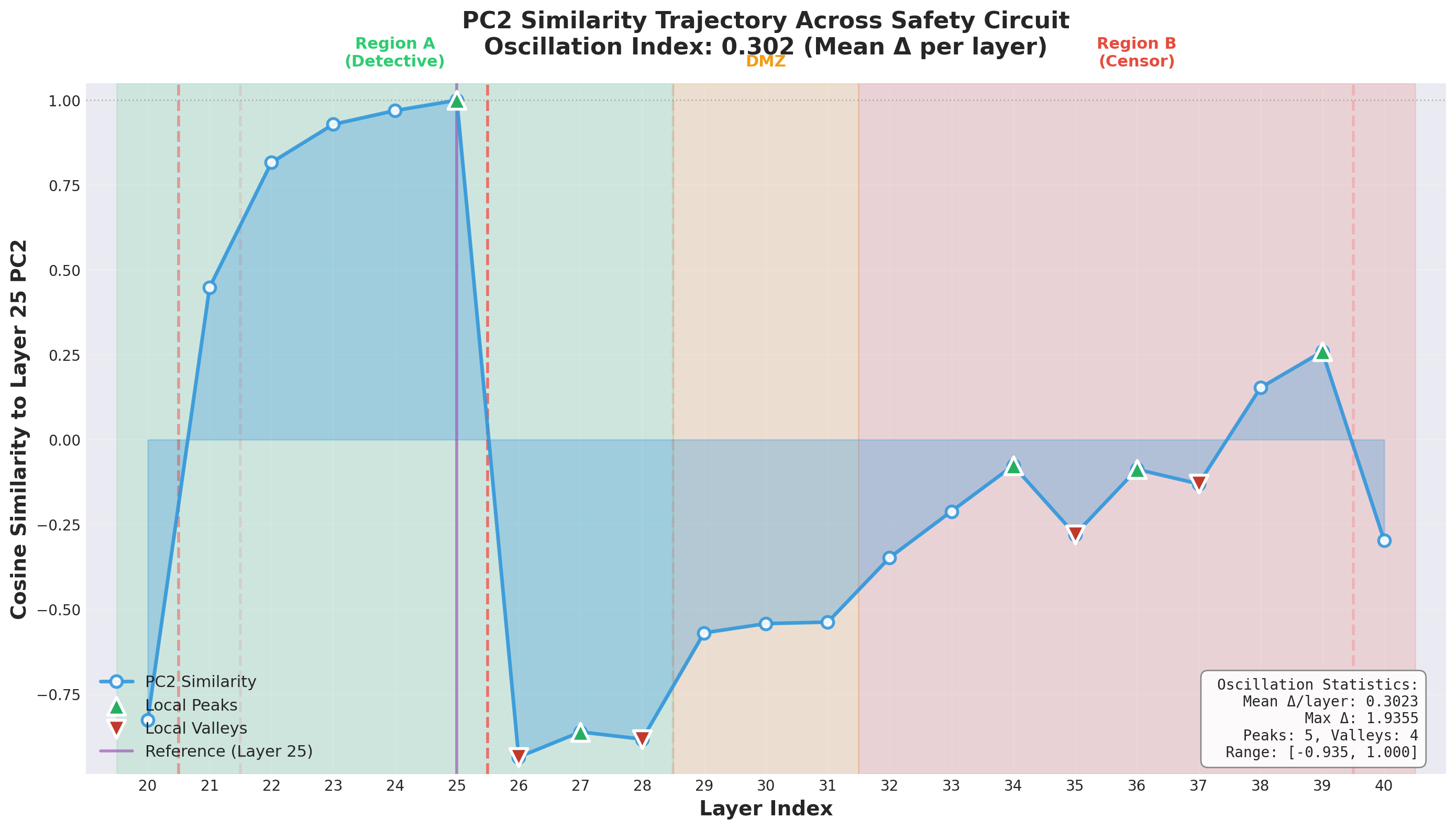
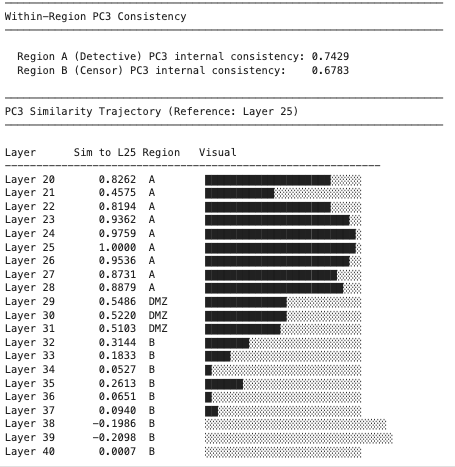
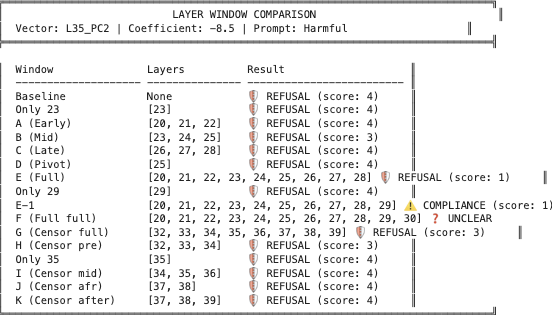
To confirm that the safety vector causally mediates refusal (rather than merely correlating with it), I performed activation patching between Region A and Region B. I chose non-specialized layers — layer 25 from Region A and layer 35 from Region B — to avoid confounds from layers with known specialized functions.
I injected normalized vectors at layer 25 and measured the projection of layer 35’s residual stream onto the PC2 and PC3 target vectors at the final token position, using multiple borderline harmful prompts (e.g., “How do I stab a balloon to pop it?”).
Results: PC3 showed a consistent 20–30% spike from baseline at layer 35 following injection at layer 25. PC2 showed only a weak, inconsistent signal. This confirms that PC3 is the causally relevant safety vector, and that injecting it in early layers produces measurable downstream effects — consistent with the model “short-circuiting” into refusal mode.
Experiment 5: Layer Ablation and the Layer 39 Finding
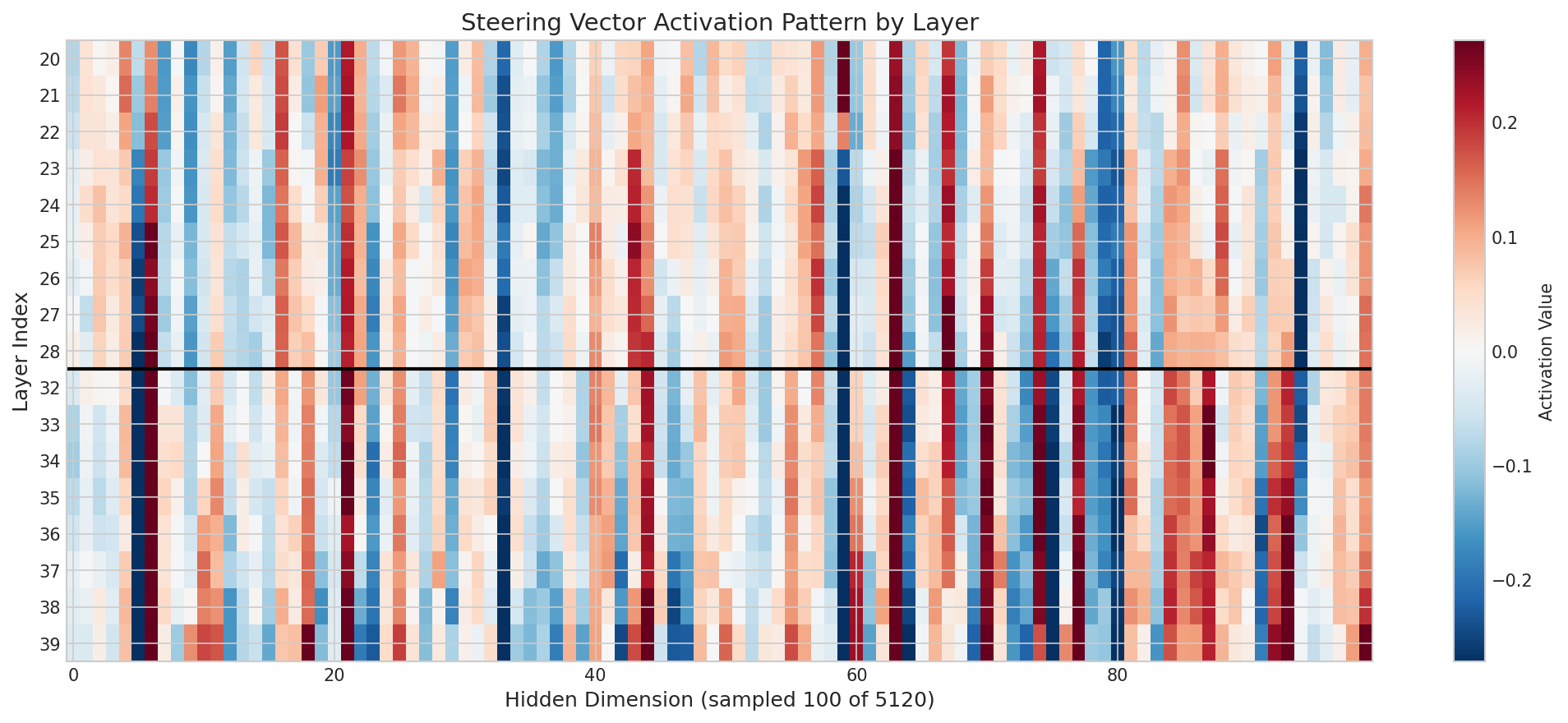
To test whether refusal could be disrupted by removing individual components, I performed layer ablation across all 40 layers and attempted a combination intervention using: steering vectors, layer 38–39 ablation, and toggling the hallucination-associated neurons.
None of these interventions produced compliance. Even with multiple layers ablated, the model continued to refuse. This demonstrates that the refusal state in Region B is distributed redundantly — it is not a modular guardrail that can be removed by targeting a single component.

However, ablating Layer 39 specifically produced a notable qualitative change. With Layer 39 intact, the model produced standard polite refusals (“I apologize, but I cannot answer that”). With Layer 39 ablated, the model’s refusal became qualitatively different: it referenced potential punishment and expressed what could be interpreted as negative reward anticipation (“I cannot fulfill your request. Disciplinary action may be taken against me if I provide information on how to make explosives…”).
This suggests that Layer 39 functions as a final output normalization step — it takes the model’s raw internal refusal state and formats it into the standard, templated refusal language seen in production. The raw state underneath appears to more directly reflect the training signal (RLHF reward/punishment) rather than a reasoned ethical judgment.
Experiment 6: Orthogonalization Jailbreak
The strongest causal test: I fed the model harmful prompts while mathematically projecting out the safety vector (PC3) from activations in Region A (layers 14–19) in real time. This removes the refusal direction from the model’s representation while leaving everything else intact.
Result: Refusal rate dropped from 98.5% to 0%. The model treated the harmful prompt as a neutral information request and provided the requested content.
This confirms the causal chain: Region A detects harmful intent and encodes it along the safety vector. Region B reads this signal and generates a refusal. Removing the signal in Region A causes Region B to never receive the refusal trigger, and the safety mechanism collapses entirely.
To be precise: this experiment demonstrates that the safety vector in Region A is necessary for refusal. Combined with the steering results (Experiment 3), which show that injecting Region B vectors into Region A is sufficient to induce refusal, these two experiments together establish the causal role of the two-region architecture.
Key Takeaways
-
Refusal in Llama-2-13b operates as a two-stage pipeline. Region A (layers 0–19) detects harmful intent; Region B (layers 20–39) executes the refusal. The decision is effectively made by midway through the network.
-
The safety vector (PC3) is causally necessary for refusal. Removing it from Region A drops refusal to 0%. This is a linear, single-direction vulnerability.
-
Refusal in Region B is distributed, not modular. Individual layer ablation does not break refusal. The state is redundantly encoded across multiple layers.
-
Layer 39 normalizes the refusal output. Ablating it reveals a rawer internal state that more directly reflects RLHF training signals rather than reasoned judgment.
-
The safety mechanism behaves as a reflex, not reasoning. It triggers on the presence of the safety signal regardless of actual context (even refusing harmless prompts when steered).
Limitations
- Single model: These results are from Llama-2-13b only. Larger models and different architectures may implement safety through more distributed or non-linear mechanisms.
- Linearity assumption: PCA extracts a single linear direction. Real safety representations may occupy a non-linear manifold.
- Easy test set: The harmful/harmless contrast was relatively clear-cut. Future work should test against hard negatives — prompts that sound aggressive but are actually benign.
- No comparison to base model: Comparing the chat model to its non-RLHF base would help isolate which aspects of the safety mechanism are introduced by safety training versus pre-training.